
مدلهای زبانی بزرگ (Large Language Models یا به اختصار LLM) نوعی شبکههای عصبی عمیق هستند که برای پردازش و تولید زبان طبیعی طراحی شدهاند. این مدلها بر پایه معماری ترنسفورمر ساخته میشوند. معماری ترنسفورمر دارای لایههای مختلفی است که از مکانیزم توجه (Attention) استفاده میکنند تا روابط بین همهٔ کلمات (توکنها) را در یک جمله بهصورت همزمان بررسی کنند. به زبان ساده، این مدلها میآموزند چگونه براساس دنبالهای از کلمات (متن ورودی) محتملترین کلمه یا توکن بعدی را پیشبینی کنند. در ادامه مراحل کلی کار یک LLM به صورت ساده توضیح داده میشود:
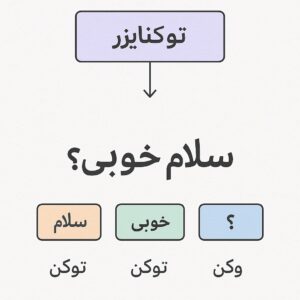
- گام اول: آمادهسازی ورودی و توکنسازی. ابتدا متن ورودی (مثلاً یک پرسش یا جمله) به توکن (واحدهای کوچک متن، معمولاً کلمات یا بخشهایی از کلمات) شکسته میشود. این کار توسط یک «توکنایزر» انجام میشود که یک دیکشنری (واژگان) ثابت از توکنها دارد. مدل فقط میتواند با توکنهایی کار کند که در این واژگان تعریف شدهاند.به عنوان مثال، جمله «گربه روی قالی» ممکن است به توکنهای «گربه», «روی», «قالی» تقسیم شود.
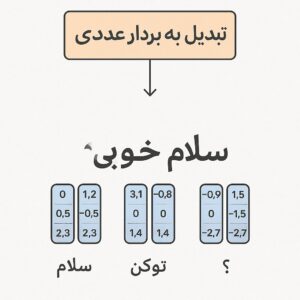
- گام دوم: تبدیل توکنها به بردارهای عددی (وردبردارها). هر توکن به یک بردار عددی در یک فضای چندبعدی نگاشت میشود. این بردارها (بردارهای جاسازی یا «embedding») نیز در واقع بخشی از پارامترهای مدل هستند. به این ترتیب، جملهٔ ورودی که مجموعهای از توکن است، به یک دنباله از بردارهای عددی تبدیل میشود که نشاندهندهٔ معانی ضمنی توکنها هستند.برای مثال، توکن «گربه» برداری دارد که مانند «گربور» و «سگ» نزدیک هم هستند چون معنیشان شبیه است.
- گام سوم: عبور از لایههای ترنسفورمر. بردارهای توکنشده وارد چندین لایهٔ ترنسفورمر میشوند. در هر لایه، مکانیزم «توجه» بررسی میکند که هر توکن به چه اندازه به سایر توکنها مرتبط است. بدین ترتیب مدل میتواند بفهمد کدام کلمات در جمله مهمتر هستند و چگونه کلمات مختلف به هم ربط دارند. علاوه بر آن، هر لایه شامل نورونهای پنهان (شبکههای عصبی) است که با وزنها و بایاسهای خاصی به پیام ورودی واکنش میدهند.
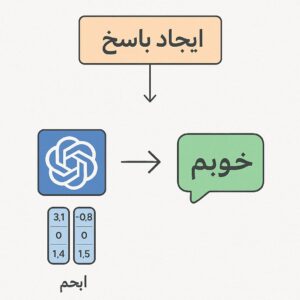
- گام چهارم: پیشبینی توکن بعدی. پس از عبور دادهها از همهٔ لایهها، مدل خروجی احتمالی از کلمات یا توکنهای ممکن برای جایگزین شدن در ادامهٔ متن تولید میکند. به عبارت دیگر، برای هر کلمهٔ ممکن یک «احتمال» محاسبه میشود. سپس معمولاً توکن با بیشترین احتمال به عنوان کلمهٔ بعدی انتخاب میشود. این روش پایهٔ عملکرد LLMها است؛ مدل تلاش میکند توکنی را پیشبینی کند که بیشترین سازگاری را با متن قبلی داشته باشد.
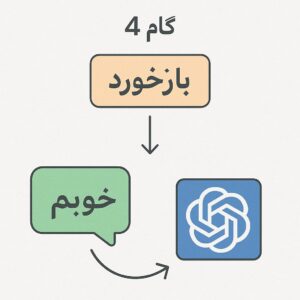
- گام پنجم: تولید متن خروجی. مدل میتواند با تکرار گام چهارم، چندین کلمه یا جملهٔ جدید بسازد. هر کلمه یا توکن پیشبینیشده به متن برگردانده میشود و در نهایت متن نهایی (پاسخ یا ادامهٔ جمله) تشکیل میشود.
مثال ساده: فرض کنید میخواهیم مدل جمله «گربه روی قالی … » را کامل کند. ابتدا مدل این جمله را به توکنهای «گربه»، «روی»، «قالی» تقسیم میکند. سپس این توکنها را به بردار عددی تبدیل میکند و از لایههای ترنسفورمر میگذراند. مدل براساس پارامترهای یادگرفتهشده، توکنی مانند «نشسته» را با احتمال بالا برای ادامهٔ جمله پیشبینی میکند. در نتیجه پاسخ نهایی ممکن است «گربه روی قالی نشسته است.» باشد. به این ترتیب، مدل با استفاده از دانشی که از آموزش روی حجم عظیمی از متن (مثلاً صفحات وب و کتابها) کسب کرده، کلمه یا جملهٔ بعدی را حدس میزند.
پارامترها در مدلهای زبانی بزرگ
پارامترها در شبکههای عصبی، بهطور خاص وزنها و بایاسهای اتصالات بین نورونها اشاره دارند. این مقادیر عددی نحوهٔ تبدیل ورودی (مثلاً بردارهای جاسازی توکنها) به خروجی را مشخص میکنند. به عبارت دیگر، هر پارامتر مانند یک درجه یا پیچ کنترلی عمل میکند که تأثیر هر ورودی بر خروجی را تعیین میکند. در مدلهای زبانی بزرگ، تعداد بسیار زیادی از این پارامترها وجود دارد. بر اساس تعریف، «پارامترها مقادیر عددی هستند که LLM در طول آموزش یاد میگیرد و برای درک زبان تنظیم میکند». برای مثال، وزن (weight) یکی از پارامترها است که میزان تأثیر یک اتصال بین دو نورون را نشان میدهد. بایاس (bias) هم پارامتری ثابت است که به خروجی یک نورون افزوده میشود تا مدل بتواند حالتهای مختلف را بهتر یاد بگیرد.
پارامترها چگونه بهدست میآیند؟
پارامترهای مدل در فرایند آموزش شکل میگیرند. در این مرحله، مدل با مجموعه بزرگی از دادههای متنی (مثلاً میلیاردها جمله از اینترنت) تغذیه میشود. هدف مدل، بهروزرسانی پارامترها طوری است که هنگام پیشبینی «کلمهٔ بعدی» کمترین خطا را داشته باشد. به عبارت دیگر، مدل بارها تلاش میکند توکن بعدی صحیح را پیشبینی کند، سپس پارامترهایش را بر اساس اختلاف بین پیشبینی و واقعیت (خطا) تنظیم میکند. این کار با روشهایی مانند گرادیان کاهشی انجام میشود. در نهایت پس از آموزش، مدل دارای پارامترهایی است که به بهترین شکل ممکن ساختار و الگوهای زبان را آموختهاند. به همین دلیل میگوییم پارامترها «یادگرفته» شدهاند؛ چون در هر تلاش آموزش، مقدارشان برای بهتر کردن پیشبینیها تنظیم میشوند.
چرا تعداد پارامترها میلیاردها است؟
دلیل اصلی تعداد بسیار زیاد پارامترها نیاز به ظرفیت بالای مدل برای یادگیری جزئیات پیچیدهٔ زبان است. هر لایه از ترنسفورمر شامل دهها یا صدها هزار نورون و هر نورون صدها اتصال دارد؛ وزن هر اتصال یک پارامتر است. با افزایش تعداد لایهها و اندازهٔ هر لایه (تعداد نورونها و ابعاد بردارها)، تعداد پارامترها به سرعت رشد میکند و به میلیاردها میرسد. به بیان دیگر، «این شبکههای عظیم شامل لایهها و گرههای زیادی هستند که هر کدام دارای وزن و بایاس ویژه خود هستند. این وزنها و بایاسها (به همراه بردارهای جاسازی) پارامترهای مدل را تشکیل میدهند. مدلهای ترنسفورمر بزرگ میتوانند میلیاردها پارامتر داشته باشند». مثلاً مدل GPT-3 حدود ۱۷۵ میلیارد پارامتر دارد، و مدلهای نسلهای بعد GPT-4، گوگل جمنای، بلوم و… پارامترهای بیشتری (صدها میلیارد یا تریلیونها) دارند.
تأثیر تعداد پارامترها بر کیفیت مدل
بهطور کلی، مدلهای بزرگتر و دارای پارامترهای بیشتر میتوانند الگوهای زبانی پیچیدهتر را یاد بگیرند و خروجیهای با کیفیتتر تولید کنند. پارامترهای بیشتر باعث میشوند مدل ظرفیت بیشتری برای «به خاطر سپردن» و «شناختن» جزئیات زبان داشته باشد. به همین دلیل، مدلهای بزرگتر معمولاً میتوانند پاسخهای طبیعیتر، دقیقتر و با خلاقیت بیشتری بدهند. برای مثال، جملات طولانی و مسائل پیچیده را بهتر از مدلهای کوچکتر حل میکنند.
با این حال، رشد تعداد پارامترها همیشه با مزایا همراه نیست. هر افزایش در پارامترها نیاز به قدرت محاسباتی و حافظه بسیار بیشتری دارد و هزینهٔ آموزش و اجرا را بالا میبرد. همچنین برخی پژوهشها نشان میدهند که پس از یک مقیاس خاص، بازدهی افزودهشده با هر پارامتر جدید کاهش مییابد (یعنی دستاورد کاهنده وجود دارد).
از سوی دیگر کیفیت دادههای آموزشی نیز بسیار مهم است. مدلی با پارامترهای زیاد ولی دادههای بیکیفیت ممکن است بد عمل کند یا خروجیهای نامناسب تولید کند. در مقابل، یک مدل کوچکتر که روی دادههای باکیفیت و مناسب آموزش دیده، میتواند در برخی کاربردها عملکرد بهتری داشته باشد. به عبارت دیگر، «بزرگتر لزوماً همیشه بهتر نیست؛ برای برخی کاربردها یک مدل کوچکتر و تخصصی میتواند بهتر از یک مدل بزرگ عمومی باشد».
آیا مدلهای بزرگتر همیشه بهتر هستند؟
پاسخ کوتاه این است: نه همیشه. مدلهای دارای پارامتر بیشتر معمولاً توانمندترند، اما نباید تنها معیار انتخاب باشد. اگر منابع محاسباتی محدود باشد یا کار مشخصی نیاز به دقت کمتری دارد، استفاده از مدل کوچکتر یا بهینهتر میتواند منطقیتر باشد. همچنین اگر دادههای آموزشی کم یا ناپایدار باشند، یک مدل بزرگ ممکن است به مشکل بخورد (مثلاً دچار «بیشبرازش» شود). همانطور که در یک راهنما اشاره شده، «مدلهای بزرگ با پارامترهای بیشتر اغلب قابلیتهای بهتری در درک و تولید متن پیچیده دارند، اما این لزوماً به معنای بهترین بودن برای همهٔ کاربردها نیست».
در عمل، پژوهشگران و مهندسان سعی میکنند بین اندازه مدل و کاربرد موردنظر تعادل برقرار کنند. گاهی با «تنظیم نهایی» (Fine-tuning) یک مدل کوچکتر روی داده خاص، نتایجی برابر یا بهتر از یک مدل بسیار بزرگ عمومی میگیرند. به همین دلیل توسعهدهندگان همواره در جستجوی ساختن مدلهایی «باهوشتر، نه صرفاً بزرگتر» هستند.
جمعبندی
مدلهای زبانی بزرگ با پردازش توکنها و استفاده از معماری ترنسفورمر، برای پیشبینی کلمات بعدی طراحی شدهاند. این مدلها با تعداد زیادی پارامتر (وزنها و بایاسها) آموزش میبینند تا قواعد پیچیده زبان را یاد بگیرند. پارامترها در طی آموزش بهطور خودکار تنظیم میشوند تا مدل بتواند پیشبینیهای بهتری ارائه دهد. افزایش پارامتر معمولاً کیفیت تولید متن مدل را بهتر میکند، اما هزینه و پیچیدگی را هم بالا میبرد و در همهٔ شرایط ضروری نیست. به همین دلیل، علاوه بر اندازه مدل، کیفیت دادهها و هدف کاربردی نیز در تعیین بهترین مدل زبانی نقش دارند.

